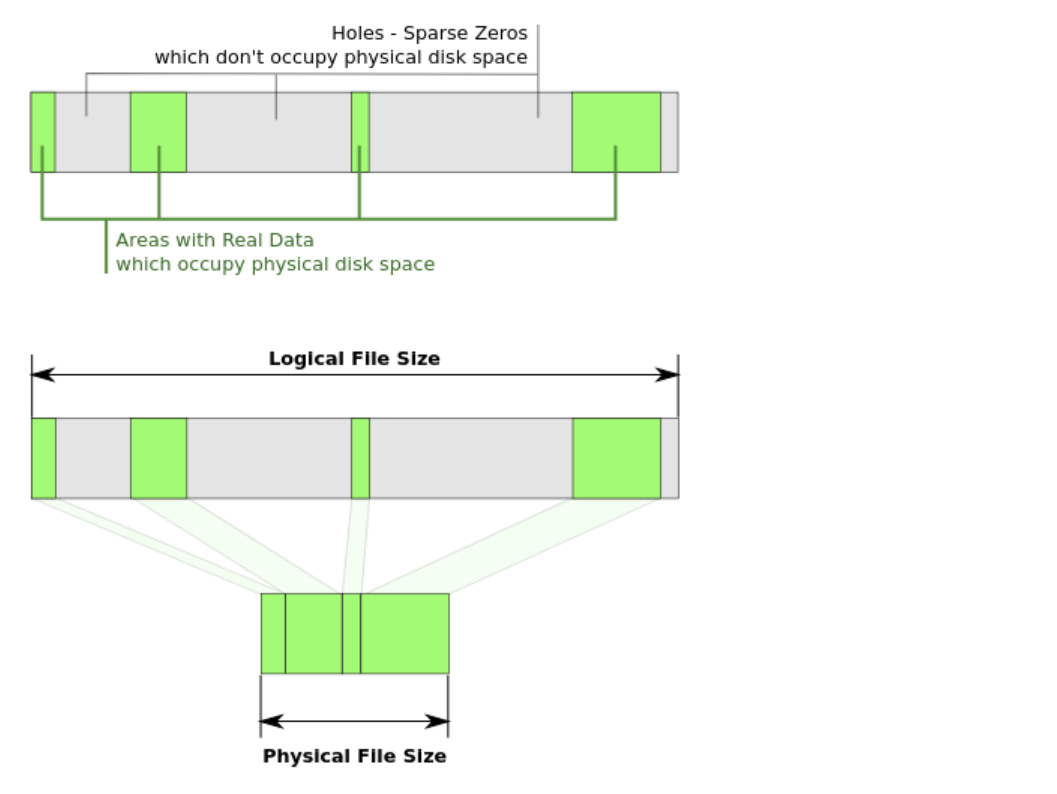
QEMU softmmu模型
本文将分析 QEMU TCG 模式下的访存模型,也就是 softmmu 的设计,基于的版本为 QEMU 6.2,架构则以 RISC-V 为例。 基本调用链1234561. target/riscv/translate.c 访存指令翻译。2. accel/tcg/cputlb.c 调用 helper 加载函数(如 helper_le_ldq_mmu)。3. 调用 load_helper 函数 1. 查 TLB,若未命中,则 tlb_fill 进行填充。 2. 处理各种特殊情况(MMIO、不对界访问等)。 3. 计算得到对应的宿主机虚拟地址 haddr = addr + entry->addend,并根据字长进行访问。 TLB 数据结构QEMU 的 softmmu 模型的核心数据结构为其 TLB 的设计,结构如下: CPUTLB12345typedef struct CPUTLB { CPUTLBCommon c; // 存储 TLB 的一系列元数据。 CPUTLBDesc d[NB_MMU_MODES]; // 慢速(二级) TLB,主要用于存储从...

OS功能挑战赛2025总结
随着最近 OS 功能挑战赛 2025 的落幕,既标志着这几个月比赛工作的结束,也标志着本人研一生活的结束。本文将作为一个简单的记录,对本次比赛的过程以及得到的经验教训做一个总结,同时也对未来的学习研究做一个展望。 比赛回顾首先说一下比赛结果—— 三等奖 ,一个稍微有些令人失望的结果。但不管如何,比赛过程中的收获却是实打实的。 项目的源代码已经开放在了 github 中,欢迎参考: LordaeronESZ/SEVFS: A simple encrypted versioning file system. 时间线接下来,我将简单梳理一下本次比赛的整个时间线。 首先是 3 月份,我们完成了比赛的报名和选题工作。其中选题工作并不那么顺利,最开始我们选题备选方案为:(1)proj121-使用哈希页表实现虚拟机的 stage-2 页表 和 (2)proj319-支持 RISC-V 架构的文件级加密文件系统。由于个人科研方向为虚拟化方向,因此两个题目中更偏向于前者。但通过对往年的参赛作品进行调研发现,已经有队伍做过了该题目并且基本完成了题目的所有要求,并最终获得了一等奖——我们再选择...
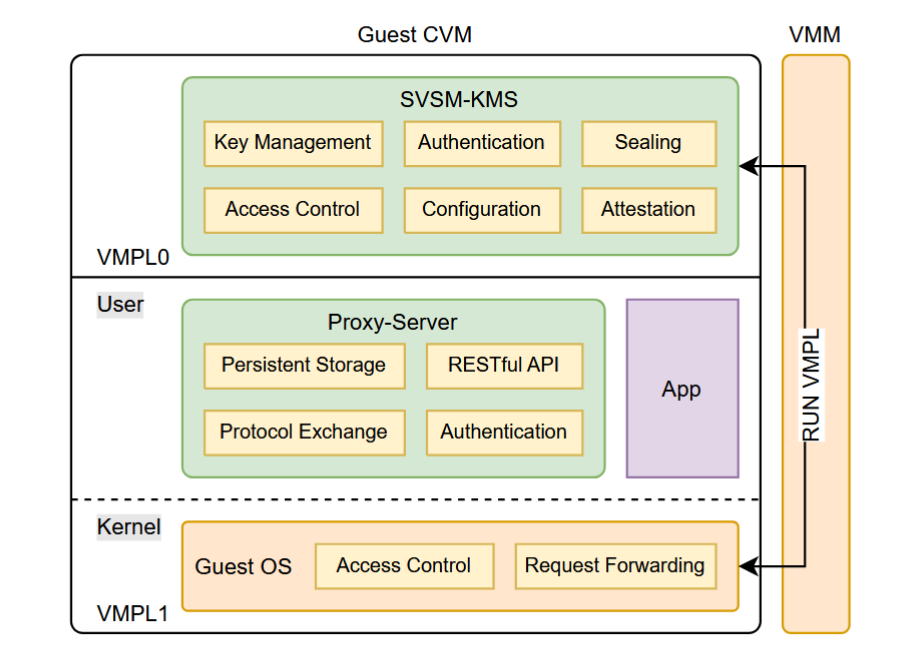
论文《SVSM-KMS:Safeguarding Keys for Cloud Services with Encrypted Virtualization》总结
本文将介绍 2024 年发表在 arXiv 上的论文《SVSM-KMS:Safeguarding Keys for Cloud Services with Encrypted Virtualization》。 解决的问题密钥管理服务是云环境中最重要的服务之一。集中式密钥管理系统(centralized Key Management System, KMS)通常提供一个统一的平台来进行密钥生成、分发、管理等操作,然而,这会导致可信计算基(TCB)过大,带来单点故障的风险。非集中式的 KMS 是一个方向,但是这会带来为维护多结点一致性的高昂的开销。 云端的安全密钥管理存在许多问题:首先云服务提供商(CSP)拥有对平台的绝对控制权,需要将其视作可信。此外,网络延迟会影响集中式的 KMS 的效率。同时,如果宿主机系统被攻破,还可能导致密钥的泄露。 为了解决这些问题,本文基于 AMD SEV-SNP 所引入的 VMPL 机制和 SVSM 特权软件,设计了 SVSM-KMS,将 KMS 放在 CVM 内的最高 VMPL 特权级,与 host 和 guest 隔离开来。具体来说,本文的贡献如...

RISC-V 架构下的裸金属程序
本文将介绍如何在 RISC-V 环境下,编写一个最简的裸金属(bare-metal)程序,该程序不依赖于操作系统的支持,计算机在启动后直接跳转到该程序开始执行。本文的目的主要是作为一个程序模板,可以对其进行扩展成为一个完整的操作系统或是常驻内存中的固件服务。 实现原理要实现计算机在启动后立马跳转到该程序执行,需要明确一点:计算机启动后执行的第一条指令是什么?或者说,PC 初始值是什么?答案根据平台的不同可能存在差异,我们的测试环境为 qemu-system-riscv64 模拟器的 virt 模型,其初始 PC 为 0x80000000。那么我们便要编写链接脚本,将需要程序的入口点链接到该地址处。 还有第二个问题:程序入口可以直接是 C 程序吗?答案是不行,至少绝大部分情况下不行。C 代码编译之后,局部作用域内变量的保存依赖于栈,因此我们必须准备好一片连续的内存区域(栈空间),并在进入 C 环境前将栈指针寄存器(SP)指向该内存区域的最高地址处(因为栈从高地址向低地址增长)。 至于栈空间的分配,通常有两种方式。首先可以编写链接脚本进行预留: 123456789101112131...
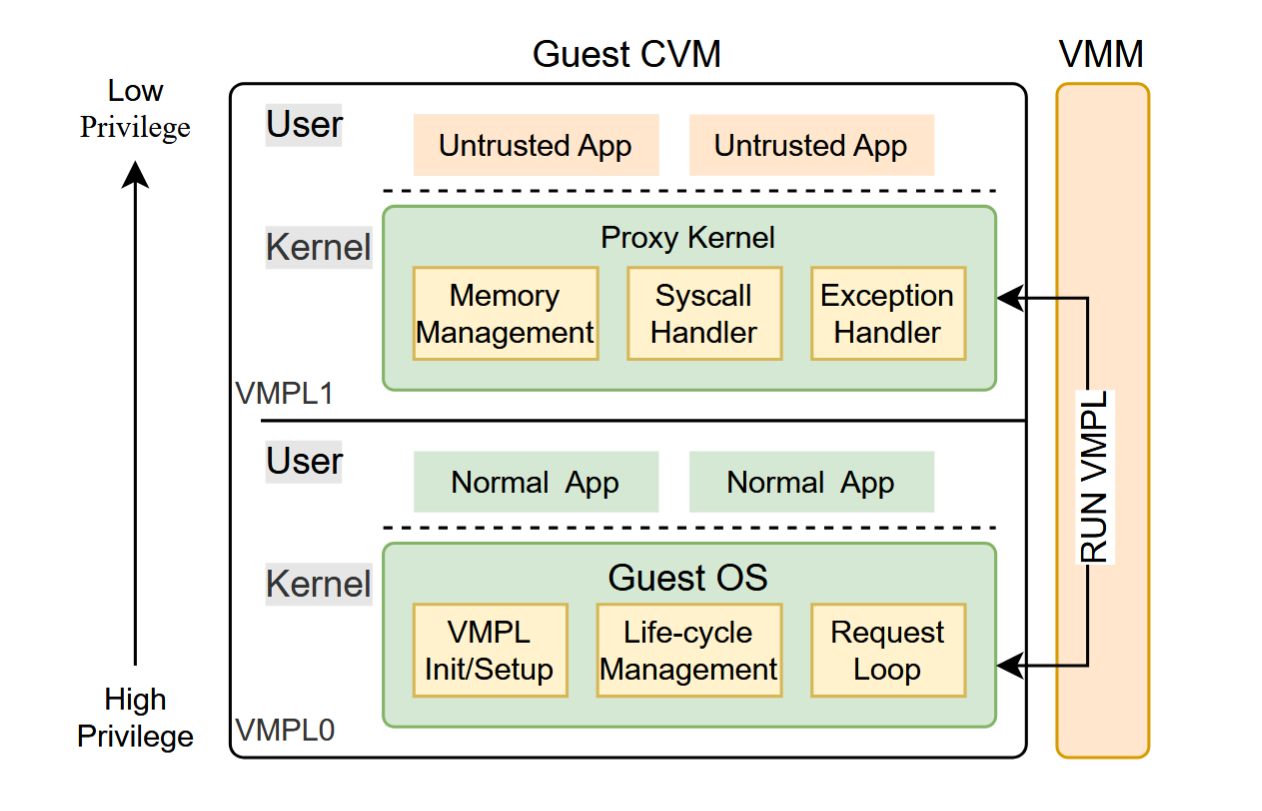
论文《Cabin:Confining Untrusted Programs within Confidential VMs》总结
本文将介绍 2024 年发表在 arXiv 上的论文《Cabin: Confining Untrusted Programs within Confidential VMs》。 解决的问题特权级划分保证系统稳定运行的最基本机制,然而传统的特权级划分存在一些不足之处:首先,由于内核庞大的代码所带来的庞大的攻击面,用户态和内核态的接口——系统调用可能会被恶意用户程序利用以绕过内核的保护机制;其次,MMU 缺乏细粒度的页面保护,x86 架构下页表项的读写权限仅由一个 R/W 位来指示,只能被配置为只读或可读可写,限制了 XOM(eXecute-Only Memory)的高效实现。 具体来说,本文工作的威胁模型基本继承自 CVM 的威胁模型,在此基础上加入了对于部分应用程序的不信任,认为其可能包含内存安全错误。贡献如下: 设计并实现了一个 CVM 内的安全进程执行框架,借助 VPML 机制,保护 guest OS 免受不可信程序的威胁。 引入系统调用异步转发、自管理内存等机制降低框架带来的性能开销,根据在 Nbench、WolfSSL 等基准测试下的性能表现,表明本框架的性能开销较低...

xv6-riscv 上下文切换代码分析
由于最近的工作涉及到编写上下文切换跳板代码的需求,因此便想将 xv6 中与此相关的代码读一读,正好之前学习时对这一块也没有看得太仔细。 系统初始化xv6 的 qemu 启动参数为 -kernel kernel/kernel -bios none,qemu 模拟器在启动时,pc 将自动跳转到预先设定的地址 0x80000000 处,而链接脚本 kernel.ld 已经将下列代码 entry.S 链接到了该地址,因此下列代码即模拟器启动后 CPU 执行的初始代码。 这段代码的作用是为每个 CPU 核心开辟属于自己的栈空间,以便后续内核代码的执行。 12345678910111213141516.section .text.global _entry_entry: # stack0 在 start.c 中定义 # 每个 CPU 固定为 4KB 的内核栈大小 # sp = stack0 + (hartid * 4096) la sp, stack0 li a0, 1024*4 csrr a1, mhar...
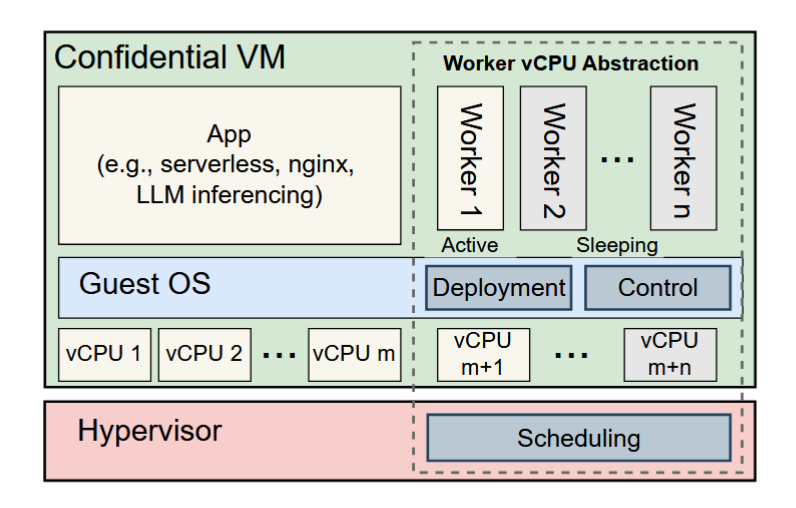
论文《Ditto:Elastic Confidential VMs with Secure and Dynamic CPU Scaling》总结
本文将介绍 2024 年发表在 arXiv 上的论文《DITTO:Elastic Confidential VMs with Secure and Dynamic CPU Scaling》。 解决的问题机密虚拟机(CVM)在带来了强大的机密性和完整性保护的同时,也带来了很多限制,导致虚拟机的性能和灵活性的下降。例如:不支持 vCPU 的热插拔(即运行中动态调整 vCPU 的数量),该特性可以用于在虚拟机运行过程中灵活调整计算能力,应用于 Serverless 等计算环境下。 虽然的商用 CVM 方案还没有任何一家支持 vCPU 热插拔,但是内存的动态调整是可行的。例如 AMD SEV-SNP 下 hypervisor 可以使用 RMPUPDATE 指令将 CVM 的内存进行回收和动态分配。 由于缺少了 vCPU 数量的动态调整能力,现有的机密无服务器环境(OpenWhisk + Kubernetes + 机密容器)要想动态调整运算能力,只能借助于启动新的 CVM,这会带来很大的性能开销。本文提出了“弹性 CVM” 和 “Woker vCPU” 的概念,能够在 CVM 环境下...
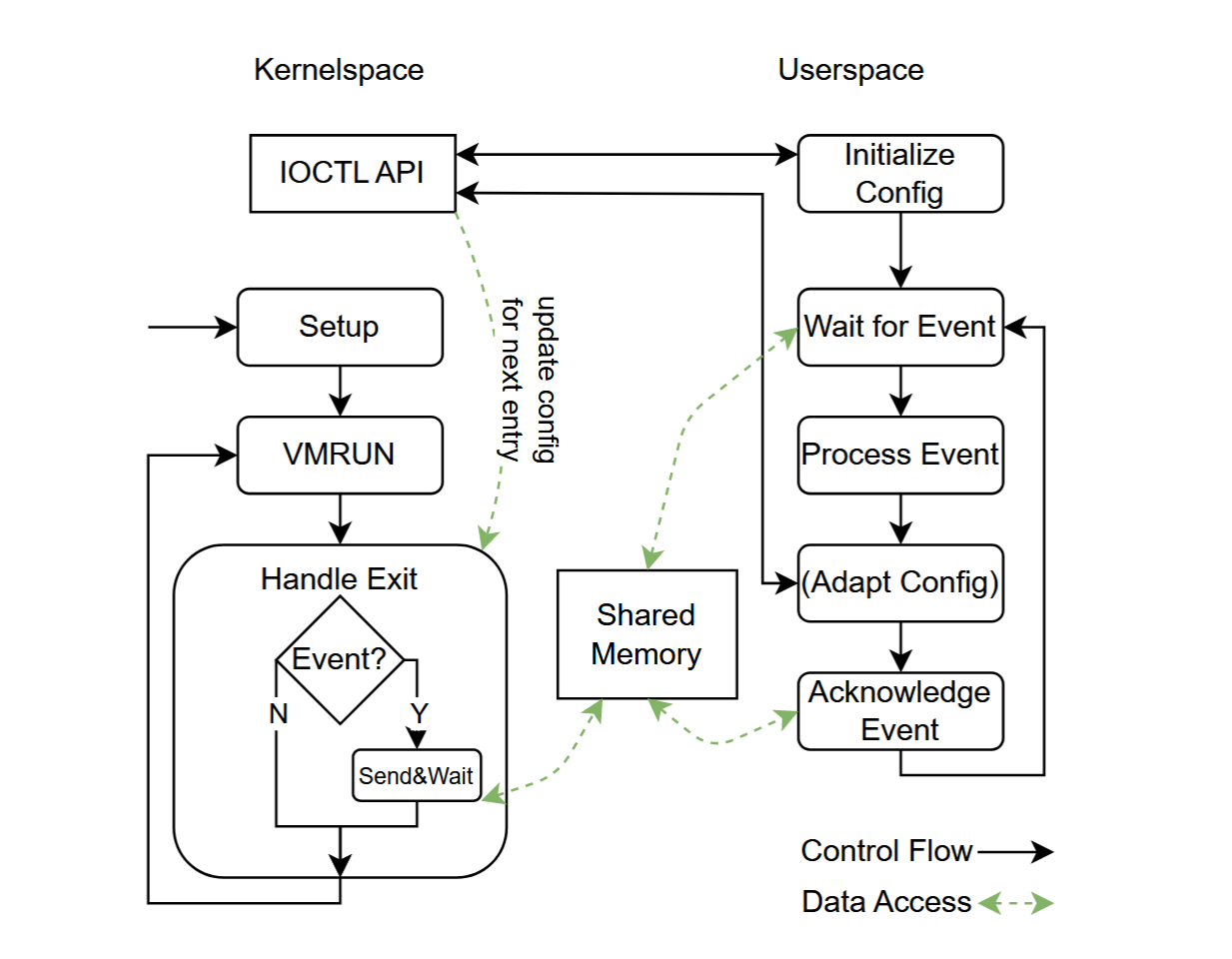
论文《SEV-Step:A Single-Stepping Framework for AMD-SEV》总结
本文将介绍发表在 arXiv 上的论文《SEV-Step: A Single-Stepping Framework for AMD-SEV》。 文章贡献 在 SEV 环境下引入了可靠(reliable)的单步执行方法。 将交互式单步执行、页面错误追踪和基于缓存组置换的缓存攻击(eviction set-based cache attacks)整合到一个可复用的框架中。 背景知识基于中断的单步执行基于中断的单步执行方法是一种通过控制处理器中断(如 APIC 时钟中断)来提升微架构攻击的时间分辨率(temporal resolution)的技术。核心思想是利用高频率的中断强制目标程序暂停执行,从而实现对微架构状态(如缓存等)的细粒度观测。 APIC 提供了高精度的定时功能,攻击者可以通过配置定时器周期性触发中断,强制目标程序在执行过程中频繁暂停。暂停后,攻击者可以利用侧信道攻击等方法,读取此时的微架构状态,再恢复下一条指令执行。这种方式将时间分辨率从页错误级别提升到了指令级。 缓存侧信道攻击 下列内容主要来自《操作系统:原理与实现》(银杏书)的在线章节:操作系统安全的 16.6....
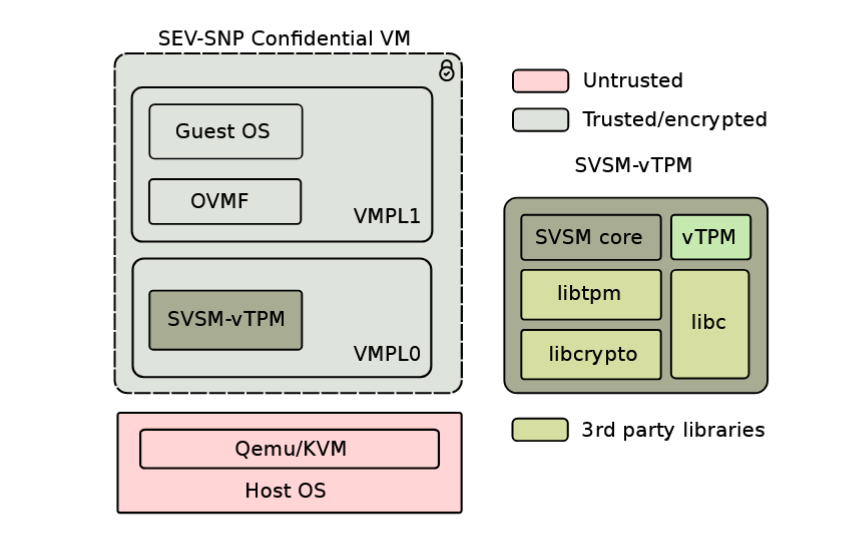
论文《Remote attestation of confidential VMs using ephemeral vTPMs》总结
本文是对 ACSAC '23 论文《Remote attestation of confidential VMs using ephemeral vTPMs》的总结,以及个人的理解和思考。 解决的问题机密虚拟机(CVM)技术为虚拟机提供一个隔离环境,防止受到 hypervisor 等高特权软件的干扰。但是这样的隔离机制作用于虚拟机运行时,在虚拟机启动过程中,此时的完整性(intergrity)保护依赖于度量启动(measured boot)和运行时证明(runtime attestation)。运行时证明需要一个硬件信任根,在物理机上,TPM 芯片可以作为这样的信任根。然而在云计算环境中,云服务提供商通过设备模拟的方式给用户提供 vTPM,使用这样的模拟设备需要信任云服务提供商,这与 CVM 的威胁模型不符。 本文作者提出了一种方法,借助 AMD SEV-SNP 技术,在 CVM 内部模拟一个 vTPM,而无需信任 hypervisor。具备以下安全要求: 隔离性:既与 guest 隔离又与 host 隔离。 安全通信:与物理 TPM 的通信是硬件级隔离的,因此 vT...

虚拟机自省技术
虚拟机自省技术(Virtual Machine Introspection)是一种通过外部监控虚拟机内部状态的技术,它能够在不依赖虚拟机内运行的软件的情况下,获取和分析虚拟机的内存、CPU 状态、磁盘活动、网络流量等数据。 以下是维基百科中对虚拟机自省技术的描述,我对其进行了中文翻译: 原文链接: Virtual machine introspection - Wikipedia 在计算机领域,虚拟机自省(Virtual Machine Introspection, VMI)是一种监控虚拟机运行状态的技术,这有助于调试和取证分析(forensic analysis)。 introspection 这个术语由 Garfinkel 和 Rosenblum 引入虚拟机领域。他们发明了一种“保护安全应用程序免受恶意软件攻击”的方法,并将其称为 VMI。如今 VMI 是不同的虚拟机取证和分析方法的通用术语。基于 VMI 的方法广泛用于安全应用程序、软件调试和系统管理。 VMI 工具可以位于虚拟机内部或外部,并通过跟踪事件(中断、内存写入等)或向虚拟机发送请求来工作。虚拟机监视器通常提供...