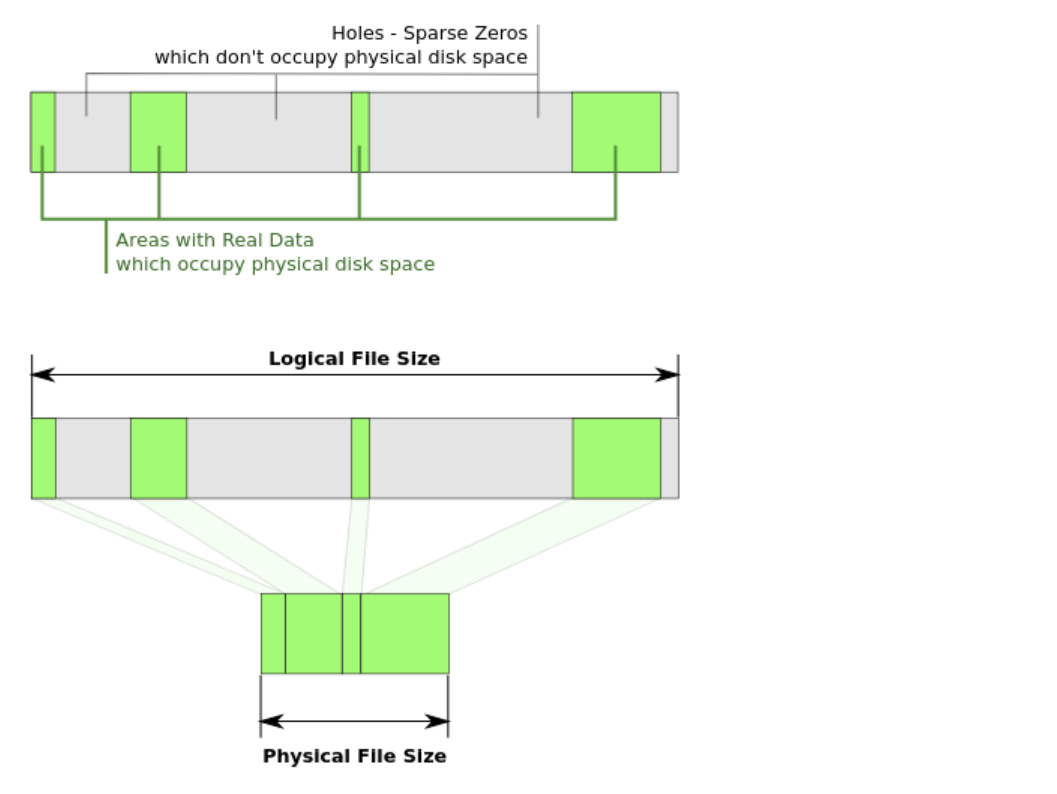
MIT6.s081 2021 Lab Page tables
Speed up system calls思路题目要求在每个进程初始化时为它的页表插入一个页表项,内核通过这样预先缓存页表项的操作,来加速特定系统调用的执行速度。 由于前不久刚过完一遍《OSTEP》,因此我认为自己对页表机制还算比较熟悉,应对本 Lab 理应比较轻松,但在真正上手的时候,还是觉得有些无所适从,无奈老老实实地把 xv6 手册的第 3 章对照着代码仔细研读了一番,从中提炼出了几个关键的函数: kernel/kalloc.c:kalloc 1void *kalloc(void); 遍历空闲链表,寻找一个可分配的物理页面。若找到,返回该页面的首(物理)地址;否则,返回 0 (空指针)。 kernel/kalloc.c:kfree 1void kfree(void *pa); 释放已分配的首地址为 pa 的物理页面,并更新空闲链表。 kernel/proc.c:allocproc 1static struct proc *allocproc(void); 遍历进程数组 proc,寻找未被使用的 struct proc。若找到,则初始化其状态,为创建一个新的页表,...

MIT6.s081 2021 Lab System calls
xv6系统调用实现不同于 Lab1 利用已实现的系统调用来实现一些用户态下的命令行程序,本 Lab 是要在内核层面实现一些系统调用。这其中难免涉及到一些对内核数据结构的操作,以及处理器体系结构(本系列 Lab 基于 RISCV)相关的内容,那么首先有必要梳理一下 xv6 下系统调用的实现过程。 xv6 系统调用的实现: 以 trace 系统调用为例,用户通过调用 user/user.h 中的函数 trace 进行系统调用。 通过调用 Perl 脚本 user/usys.pl 生成的一系列汇编代码,该汇编代码的作用是设置寄存器的内容并实现用户态到内核态的切换,内核后续针对寄存器中的内容执行相应的系统调用操作。以下是对 user/usys.pl 代码的逐行解析: #!/usr/bin/perl -w:这是一个Perl脚本的“shebang”行,指定使用/usr/bin/perl解释器执行此脚本,并开启警告(-w)选项。 print "# generated by usys.pl - do not edit\n";:打印注释说明此文件是由usys.pl脚本...

MIT6.s081 2021 Lab Utilities
Boot xv6按照示例切换到 util 分支后,看到目录下包含 Makefile 文件,执行 make qemu 即可。 sleep思路借助系统调用 sleep 实现一个命令行程序,关键是要找到封装了系统调用的 C 函数的位置,根据提示: … user/user.h for the C definition of sleep callable from a user program … 可知该函数的声明位于 user.h 头文件中,声明方式很简单: 1int sleep(int); 将其“拷贝”(include)到需要编写的代码 user/sleep.c 中,调用 sleep(<睡眠时间>) 即可。 最后,按照提示,将编写的 sleep 代码添加到 Makefile 的 UPROGS 中,添加后如下所示: 123456789101112131415161718UPROGS=\ $U/_cat\ $U/_echo\ $U/_forktest\ $U/_grep\ $U/_init\ $U/_kill\ $U/_ln\ ...

OSTEP Projects:KV
本文将介绍操作系统导论(Operating Systems: Three Easy Pieces)作者所开源的操作系统相关课程项目 的 KV 部分,包含个人的代码实现和设计思路。 思路题目要求实现一个最简单的数据库,以支持数据的持久化。 每个操作由格式为 op,[arg1],[arg2] 的命令给出,那么首先要解决的问题就是参数的分离,再根据操作符 op 来对不同的操作进行特殊处理。字符串划分这里采用的是 strsep() 函数:该函数接收两个参数 char** stringp 和 const char* delim,stringp 是指向待分割字符串 string 的指针,delim 则是指定的分隔符,该函数的操作是查找 string 中第一个 delim 的位置 it,并将 stringp 指向 string 中 it + 1 的位置,同时返回string 开头到 it 所有字符所构成的子串(加上 '\0' 终结符)。 插入操作没什么好说的,直接使用 fprintf() 写入文件即可。对于查找和删除,则需要将数据从文件(数据库)中读取到内存,存储在特定的数...

OSTEP Projects:Reverse
本文将介绍操作系统导论(Operating Systems: Three Easy Pieces)作者所开源的操作系统相关课程项目 的 Reverse 部分,包含个人的代码实现和设计思路。 思路题目的要求很简单:按行读取数据,读取完成后将所读取到的所有行反向输出(行间反向,行内不变)。但代码实现上却包含不少细节。 首先是核心问题:如何将读取到行反向输出?首先可以确定的一点是:在所有行读取完成之前,读取到的每一个行都需要进行保存。那么,利用什么数据结构进行保存呢?我们需要这个数据结构能够确定输入的不同行之间的前后相对关系,因此想到使用线性表。由于最终读取到的行数是不确定的,因此不能使用一个固定大小的数组,而应该使用可变长的线性表,如链表、动态数组。而又因为可变数组的扩容操作比较耗时,且我们并不需要对元素进行随机访问,只需要最后输出的时候进行顺序遍历,因此链表就成为了最佳选择。 反转的具体实现可以参考经典问题反转链表,设定一个前驱结点 pre 和当前结点 cur,每次读取到新的行,就动态申请存储该行数据的内存空间,并将 cur 指向这块内存空间,然后将 cur 的 next 域指向...

OSTEP Projects:Unix Utilities
本文将介绍操作系统导论(Operating Systems: Three Easy Pieces)作者所开源的操作系统相关课程项目 的 Unix Utilities 部分,包含个人的代码实现和设计思路。 wcat思路要实现一个 wcat 命令,打印从文件中读取到的所有字符。 编写一个 for 循环遍历所有的参数(需要读取的文件的路径),打开该文件,依照 README 中的提示使用 fgets() 每次读取一行,并将读取到的字符串打印到标准输出即可。 代码1234567891011121314151617181920#include <stdio.h>#include <stdlib.h>#define BUF_SIZE 1024int main(int argc, char* argv[]) { char buffer[BUF_SIZE]; for (int i = 1; i < argc; ++i) { FILE* fp = fopen(argv[i], "r"); if (fp == NULL) &#...

高效的区间二叉搜索树:线段树
与树状数组类似,线段树也是一种用来维护区间信息的数据结构,可以在对数时间复杂度内实现更新和查询等操作。但相较于树状数组多用于前缀和查询不同,线段树的应用范围更为广泛,例如区间最值等问题,代价是需要消耗更多的存储空间。 结构对于一个长度为 7 的数组,根据该数组 nums 元素建立的线段树结构如下图所示。 每个结点存储的值为区间 nums[L ~ R] 的元素和,其中根节点对应的 L = 0, R = 6,即整个数组的元素和。然后每一层的结点将区间均分为 [L, (L + R) / 2] 和 [(L + R) / 2 + 1, R] 两部分。注意按此方式进行划分,得到的两个子区间始终满足:左右区间长度分别为 len1 和 len2,且 len1 == len2 || len1 == len2 + 1。不难得知:这样的结构构成一个完全二叉树,因此使用顺序存储将会变得很方便:根节点下标为 0;对于每个下标为 idx 的结点,其左孩子下标为 2 * idx + 1,右孩子下标为 2 * idx + 2。 构造由于叶子结点的 L 和 R 相等,其值正好为 nums[L],而每个父结点的值...

自用耳机盘点
最近几个月看了不少耳机相关的内容,初步了解了一些耳机的参数指标以及选购方案,同时也给自己使用的耳机进行了一波更新换代。本文就简单盘点一下自己之前用过的和现在正在使用的耳机,内容完全基于个人的使用体验。 已退役赛睿 Arctis9x 主要是为了无线连接 xbox 而购入。买之前看了不少网上的评价,包括视频评测以及 RTINGS 网站上的测试,感觉很不错,但是这耳机并没有国行版本,而且海外版售价高达 200 美元,对我而言实在是太贵,就在淘宝花 398 购入了一副所谓的“9成新”的“洋垃圾”。 单就产品本身的素质来说,我觉得还是很不错的。尽管作为游戏耳机,但它的音乐表现依然非常出色,三频的表现十分均衡。参考 RTINGS 网站上对于 9x 的评测,其中 Neutral Sound 项评分高达 7.8 分并给出了 “satisfactory” 的评价。麦克风质量也相当不错,这根可伸缩的麦克风虽小,但却拥有优秀的收音质量和降噪能力,不过我也只是拿到手的时候测试了一下,并没有怎么使用。佩戴方面,耳机头梁采用了松紧带的设计,使得佩戴时不至于压头。耳罩不算很透气,夏天佩戴可能会比较热,但好在相...

动态前缀和数组:树状数组
前缀和的不足前缀和是一种常见的算法思想,能够实现在常数时间复杂度下得到某个子区间内所有元素和。以一维数组 nums 为例,定义前缀和数组 preSum,preSum[i] 表示 nums 前 i 个元素的和,利用动态规划的思想,易得 preSum[i] = preSum[i - 1] + nums[i] 的递推关系,因此构造一个前缀和数组的时间复杂度为 O(n),而查询前 i 个元素的和只需查询 preSum[i] 的值,为常数时间。 前缀和方法在数组元素不发生改变的情况下十分高效,但如果数组元素可能会发生改变,与朴素求和做法(不使用前缀和数组,而是直接遍历区间元素累计求和)相比,前缀和数组需要 O(n) 的时间来进行更新。这两种做法要么查询是 O(1)、更新是 O(n),要么查询是 O(n)、更新是 O(1),那有没有一种折衷的方案,使得查询和更新效率都不至于太低呢?本文将介绍的树状数组就符合这样的条件。 树状数组查询由正整数的二进制表示可知,任何一个正整数都可以拆分为为若干个不重复的 2 的幂之和。那么对于一个下标从 1 开始且长度为 n 的数组,它的任意下标 i (1 &...

从机器指令的角度看一些位级操作
C/C++ 中有时会遇到一些位级操作,通常是一些隐式的类型转换,它们往往很难凭借高级语言层面的直觉来理解或记忆。本文旨在分析这些操作对应的汇编代码,从机器指令的角度来理解这类操作。 补码数转换为更长的无符号数12345int main() { short a = -12345; unsigned b = a; cout << a << " " << b << endl; // -12345 4294954951} 首先看以上这个示例,一个短整型数据(2 字节)强制类型转换为无符号整型数据(4 字节)之后,得到的值却是一个看似毫不相关的结果。 123456void showBytes(unsigned char* ptr, size_t sz) { for (int i = 0; i < sz; ++i) { printf("%.2x ", ptr[i]); } printf("\n");} 首先,为了更好...