2022年游戏总结
今年由于要准备考研,博客几乎没怎么更新,游戏玩的也比较少,算上填坑、试玩、弃坑的粗略计算大概 20 款,其中不乏近年的新游戏以及一直想补的老游戏,以下是从中选出的几款个人觉得比较有的聊的作品。 勇者斗恶龙11s 寻觅逝去的时光 国民级 jrpg 系列的最新作品,各方面都非常均衡,角色构筑、战斗系统、隐藏要素的设计已经相当成熟。给我印象最深刻的还是本作的数值设计,将游戏流程的难度曲线设置的非常平缓,正常推进流程的情况下,既不会让战斗太过困难,也不会让战斗太过简单,整体战斗节奏非常舒适。剧情部分虽然较为王道,但人物性格塑造不错,能够让人代入其中,同时也有诸如人鱼的故事这样动人的剧情。 本作作为传统 jrpg 给我的感觉就是一切做的都很不错,但总感觉还差那么一口气,整体上设计还是过于保守,没有让我感到特别惊艳的地方。同时很多设计放在今天来看确实有点过时了,主要还是大量无聊的重复劳动,尽管特别的二周目剧情算是一个亮点,但也意味着要重新体验一遍几乎一样的流程,放在今天确实是很难以让人坚持的。另外本作的配乐由于大量沿用了以往作品的配乐,原创配乐不多,虽然单听确实还不错,但与游戏本身的故事结...

LeetCode周赛总结 第327场
由于考研等因素的影响,已经时隔一年没有参加力扣周赛了,长时间没有好好琢磨算法题,思维敏捷度确实有所下降,好在这次周赛前两题都没有什么难度,但第三题却把简单问题想复杂了,第四题就基本上都没怎么读题了。。。 正整数和负整数的最大计数题目链接正整数和负整数的最大计数 解题思路直接依照题意统计该数组中正整数和负整数的个数,然后返回较大个数即可,送分题。 解题代码123456789101112131415class Solution {public: int maximumCount(vector<int>& nums) { int cnt1 = 0, cnt2 = 0; for (int i = 0; i < nums.size(); ++i) { if (nums[i] > 0) { ++cnt1; } else if (nums[i] < 0) { ...
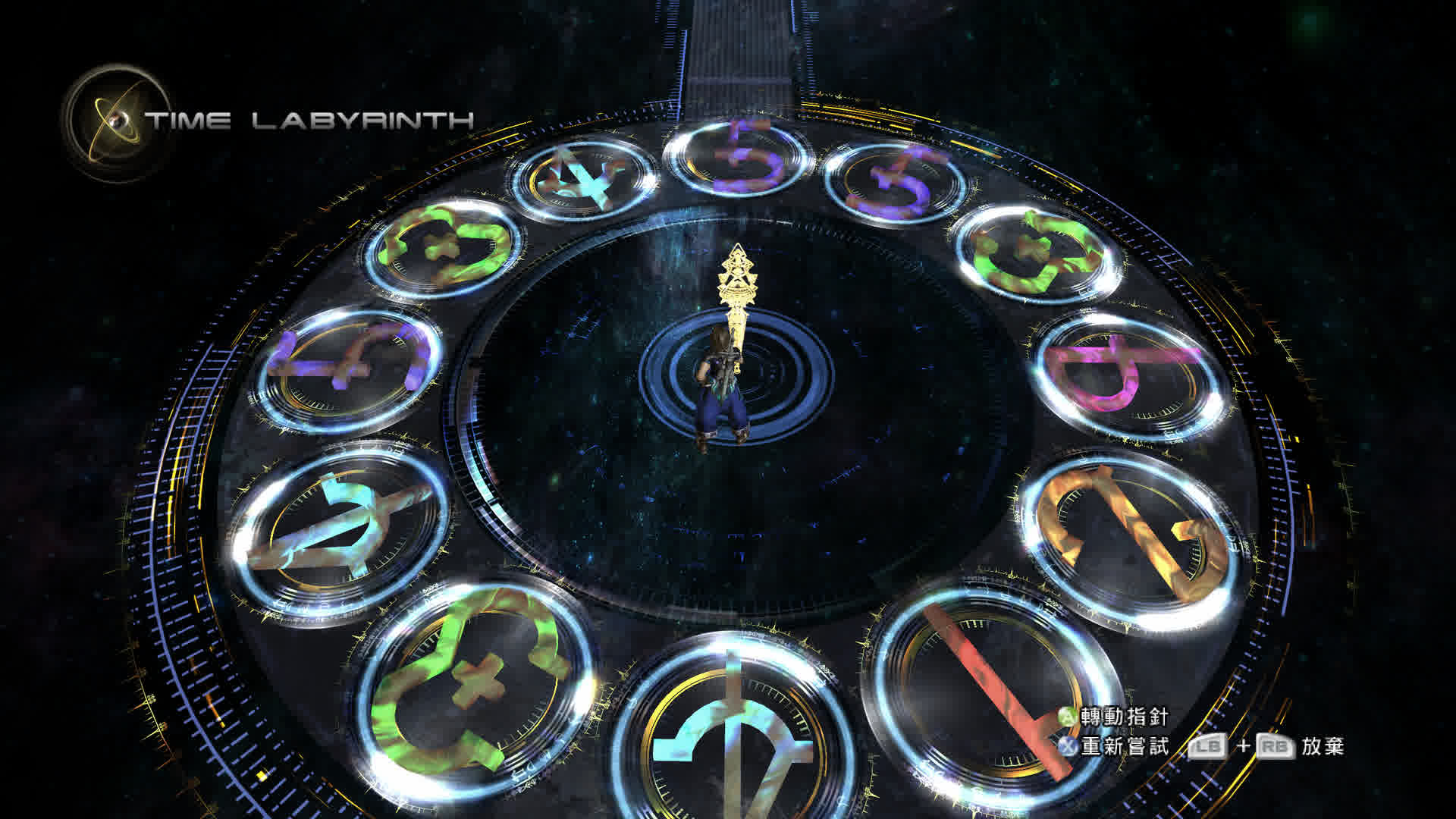
用DFS解决最终幻想13-2时钟谜题
最近在补 XGP 中的最终幻想13-2时,遇到一个时钟谜题,感觉挺有意思,就像尝试用搜索算法将其解决。 问题描述如下图所示,有一个时钟,包含个结点,每个节点有一个数字标识,玩家最开始可以任意选择一个结点,选择后,该结点被消除且指针会指向该结点的位置,根据该节点的数字值 n 分裂为两根指针分别向顺时针方向和逆时针方向旋转 n 个的单位长度。此后每次玩家只能选择指针指向的结点,选择结点后结点被消除,两指针合并指向选择结点的位置并按上述描述进行分裂和旋转,玩家需要将所有节点消除才能胜利。 注:玩家无法选择已经被消除的结点,若分裂旋转后的两指针均位于已被消除的结点位置,则判定游戏失败。 算法思路本问题很容易想到利用深度优先搜索来解决,选择一个结点作为开始,如第一次选择 12 点钟位置的结点,(以下为了方便,按结点在时钟中排布位置 n 称作结点 n)该结点值为 5,则选中后分别向顺时针和逆时针方向旋转到达结点 5 和 结点 7,这就产生了两个分支(相当于二叉树的左右子树),分别选择这两个结点继续搜索,若结点到达了一个已被访问过的结点(即该结点已被消除),则终止该方向上的搜索,并进行回溯...

Ping命令的实现
Ping (Packet Internet Groper)是一种因特网包探索器,用于测试网络连接量的程序。本文将基于 Socket 编程,实现一个基本的 Ping 命令程序。 ICMP 报文分析ICMP 报文捕获在控制台输入 ping 202.195.147.248,对该目的主机发起请求,可以看到控制台输出了一系列统计信息:4 个数据包全部接收并且往返时间为 5 ms(较短),表明与该主机之间的连接畅通。 使用 Wireshark 工具捕获 icmp 数据包,为了避免无关数据包的干扰,可以使用 filter 对数据包进行过滤,在上部栏输入 ip.src == 202.195.147.248 or ip.dst == 202.195.147.248,表明只筛选源地址或目的地址为 202.195.147.248 的数据包,最终可以得到数据包的内容。 Wireshark 数据包分析根据 ICMP 报文的格式进行分析: Type:数据包类型,占 1 Byte,为 0x00,代表回送报文。 Code:代码部分,占 1 Byte,为 0x00. Checksum:检验和,占 2 B...

人工智能作业 使用遗传算法解决旅行商问题
遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的。是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。本文利用遗传算法解决经典的NP问题——旅行商问题,并加深对该算法的理解。 问题描述有若干个城市,每个城市给定一个坐标,一个旅行商需要经过每个城市各一遍且不能重复经过城市,起点可以任意选择,求旅行商经过所有城市的总距离的最小值及其最优路径。 数据结构与算法设计数据结构设计 struct point 从文本提取的城市的坐标数据,包含 id, x, y. const int idNum = 100; // 种群个体数 表示种群的个体数目,即每次迭代所包含的数据的个数。 const double variProbability = 0.05; // 变异概率 遗传过程可能导致变异,变异次数 = 变异概率 * 种群个体数。 vector<point> coords; // 各点坐标 从文本...

停止等待协议的模拟实现
协议原理 设计思路基本传输本次实验我采用了程序模拟的方式实现。发送方和接收方都为一个数组,传输过程即为发送方数组向接收方数组传递数据,并使用随机数生成的方式模拟传输过程中可能出现的差错,并且传输时间也为一个在 50 - 150 ms 间的随机数,用一个迭代器来模拟此时发送方的数据位置。 传输过程为一个循环语句,终止条件为发送迭代器到达发送方数组的末尾位置。 选择重传每次进行传输,传输时间就会累加,在一轮传输的最后判断累计时间是否超过了规定 tout,如果未超过,代表数据成功接收,发送迭代器自增 1。 否则,不进行操作,下一次循环将会再次尝试发送该数据。 舍弃重复帧存在这么一种情况,接收方成功接收了发送方的数据,并返回了一个 ACK 帧,但是此 ACK 帧还未到达发送方就已被其判定为超时,那么发送方将会重新发送上一次的数据帧,若该数据帧成功到达接收方,那么接收方需要将该数据帧舍弃(因此上一次传输时接收方已成功接受了该数据帧)。实现方法是判断接受数组的最后一个元素(即上一次接收的元素)是否与此时接受的相同,若相同,则不接收,并重新发送 ACK 帧。 代码实现1234567891011...

人工智能作业 使用K-means算法进行聚类分析
本文将介绍如何使用 K-means 算法对给定的坐标数据进行聚类分析。 使用K-means算法进行聚类分析问题描述 K-means算法对data中数据进行聚类分析 (1)算法原理描述 (2)算法结构 (3)写出K-means具体功能函数(不能直接调用sklearn.cluster(Means)功能函数)具体函数功能中返回值包括 数据类标签,累中心,输入包括:数据,类别数 (4)可视化画图,不同类数据采用不同颜色 (5)算法分析 类类方差,平均方差,不同初始点对聚类结果的影响? 如何解决? 算法描述 数据结构设计: 数据点使用自定义数据类型point,包含x和y两个变量。 中心点一个大小为k的数组center进行存储,从文本中提取的坐标数据使用可变数组coords进行存储,不同的坐标点分组采用一个可变的二维数组group进行存储。 函数介绍: extraCoords(): 从文本文件中提取坐标数据并存入coords中,提取算法为:首先使用传入文件路径初始化文件IO流fileStream,再逐个输出fileStream中的数据。若为字母,则不接收。否则两个一组...

人工智能作业 使用AStar算法解决八数码问题
八数码问题是一个经典的搜索问题,本文将介绍如何使用启发式搜索—— AStar 算法来求解八数码问题。 使用AStar算法解决八数码问题问题描述 八数码问题的A星搜索算法实现 要求:设计估价函数,并采用c或python编程实现,以八数码为例演示A星算法的搜索过程,争取做到直观、清晰地演示算法,代码要适当加注释。 八数码难题:在3×3方格棋盘上,分别放置了标有数字1,2,3,4,5,6,7,8的八张牌,初始状态S0可自己随机设定,使用的操作有:空格上移,空格左移,空格右移,空格下移。试采用A*算法编一程序实现这一搜索过程。 算法描述预估值的设计A* 算法的花费为 f(n) = g(n) + h(n),其中 g(n) 为搜索深度,定义为状态单元 state 的成员变量,在每次生成子节点时将其加一。h(n) 为不对位的将牌数,将该部分的计算重载于 state 的小于运算符中,并将 f(n) = g(n) + h(n) 的值作为状态单元的比较值。 数据结构设计 每个状态用一个结构体表示,其中 depth 为状态深度,str 为该状态字符串,并重载小于运算符用于计算最优。 open 表使...

C++代码优化 Chapter2
本文将继续介绍一些常见的 C++ 代码优化技巧,本文为该系列的第二章,未来不定期更新。 非必要时使用常量引用在上一章我们介绍了在进行函数的参数传递时,尤其对于所占内存空间较大的参数的传递,为了避免拷贝所带来的不必要的性能开销,应当尽量使用引用传递。并且,当该函数不需要对传入的参数进行更改时,应当在参数类型前添加 const 关键字表示这是一个常量引用。 可能有朋友认为这里的 const 关键字的添加并不是必要的,但这样会带来两个问题:首先便是程序的可读性的下降,如果不添加 const 关键字,用户可能会认为该函数的变量是可更改的。其次它还将导致字面值将无法作为该函数的参数进行传递。所谓字面值,就是指代码中用数字或字符直接表示出来的常量(例如 1, "hello world"),这部分数据嵌入在程序中,当程序运行时被复制到内存的常量区,该区域为只读区域。示例如下: 1234567891011int findChar(std::string& s, char target) { for (int i = 0; i < s.size(); +...

循环语句中指针赋值出错
最近在写人工智能作业的时候遇到了一点问题,就是在循环语句中对指针类型赋值出现错误,导致所有的结点的前驱指针最终指向自身。 问题描述以下使用一个简单的示例来模拟当时出现的问题。 MyStruct 为一个自定义结构体类型,包含数据成员 val 和前驱结点 pre。首先将初始结点(0,nullptr)加入队列 Q,随后在每次循环中,用变量 fs 接收队列 Q 的队首元素并将其出队,并根据该结点生成一个新结点,该新结点 val = fs.val + 1,且将其前驱结点设为 fs 并加入到队列 Q 中。直到 fs.val >= 5 时退出循环。 1234567891011121314151617181920212223struct MyStruct{ int val; MyStruct* pre; MyStruct(int v = 0, MyStruct* p = nullptr) : val(v), pre(p) {}};int main(){ std::queue<MyStruct> Q; Q.emplace(0, n...